Franco Santiago Caspe
Supervisors: Mark Sandler - Andrew McPherson
Queen Mary University of London - Centre for Digital Music
Additional Material: Audio Examples and Videos
This website contains audio examples and videos, as well to relevant links to additional material referenced in the thesis.
Chapter 5: Tone Transfer with FM Synthesis
Audio Examples
You can access the audio examples at the corresponding website:
Envelope Learning paper website
FM Tone Transfer Plugin
Download link: FM tone transfer Plugin
Demo Video
Chapter 6: Representation Learning for Low-Latency Interaction
BRAVE Audio Examples
The full collection of audio examples for the chapter is available at the paper website.
Timbre Transfer with BRAVE
We also present an excerpt of the audio examples, highlighting the reconstruction results of percussive and tonal sounds of RAVE and BRAVE models trained on the Filosax and Drumset datasets.
Models Trained on the Drumset Dataset
We encode and decode original excerpts of Drumset, Beatbox and Candombe datasets, using RAVE and BRAVE models trained on Drumset, and present the results on the following table.
| Instrument | Original | RAVE (Trained on Drumset) | BRAVE (Trained on Drumset) |
|---|---|---|---|
| Drumset | |||
| Beatbox | |||
| Candombe |
Models Trained on the Filosax Dataset
We encode and decode original excerpts of the Filosax, Svoice and Viola datasets, using RAVE and BRAVE models trained on Filosax, and present the results on the following table.
| Instrument | Original | RAVE (Trained on Filosax) | BRAVE (Trained on Filosax) |
|---|---|---|---|
| Filosax | |||
| Svoice | |||
| Viola |
BRAVE Audio Plugin and Demo Videos
This link includes both a plugin to run BRAVE models and a set of demo videos showing the capabilities of low-latency representation learning.
Chapter 7: Interaction Design with Neural Audio
Here we present several audio recordings of different BRAVE training configurations, discussed in the thesis. Each yields different representations.
Rendered Transformations for different BRAVE Configurations
| Sound Example | Acoustic Guitar: Chord and Arpeggio | Electric Guitar: Muted Strings |
|---|---|---|
| Original (Input) |

|
|
| FM Tone Transfer (BRASS) |

|
|
| BRAVE Original |

|
|
| BRAVE Two-Phase |

|
|
| BRAVE One-Phase |
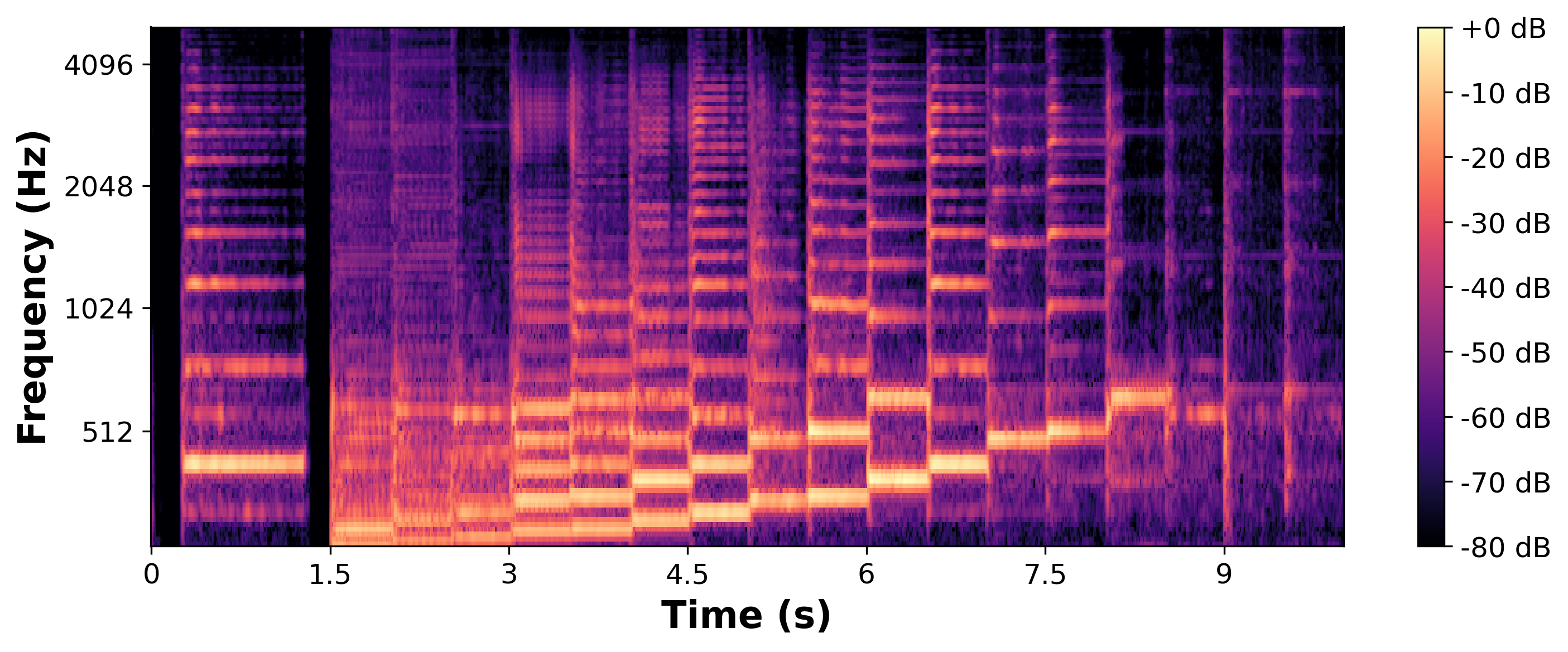
|
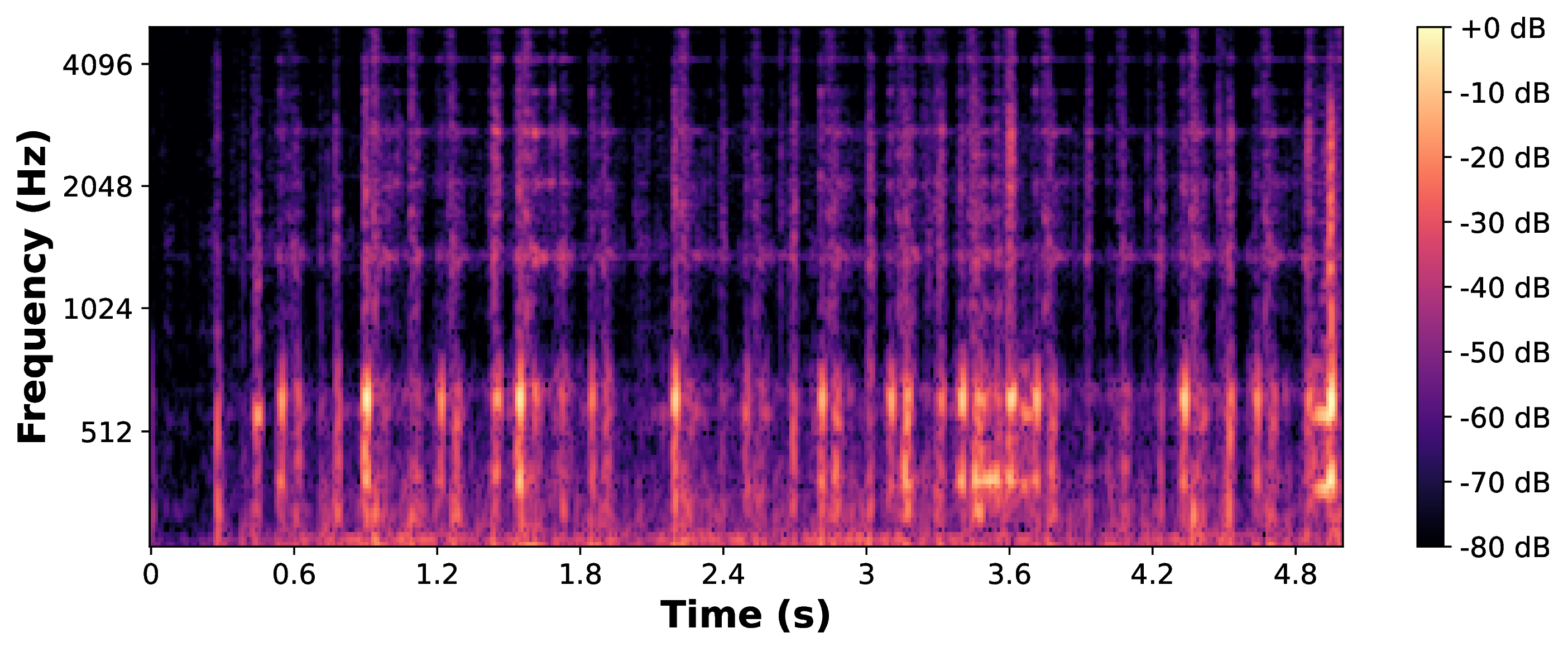
|
| BRAVE Grafted (VCTK) |

|
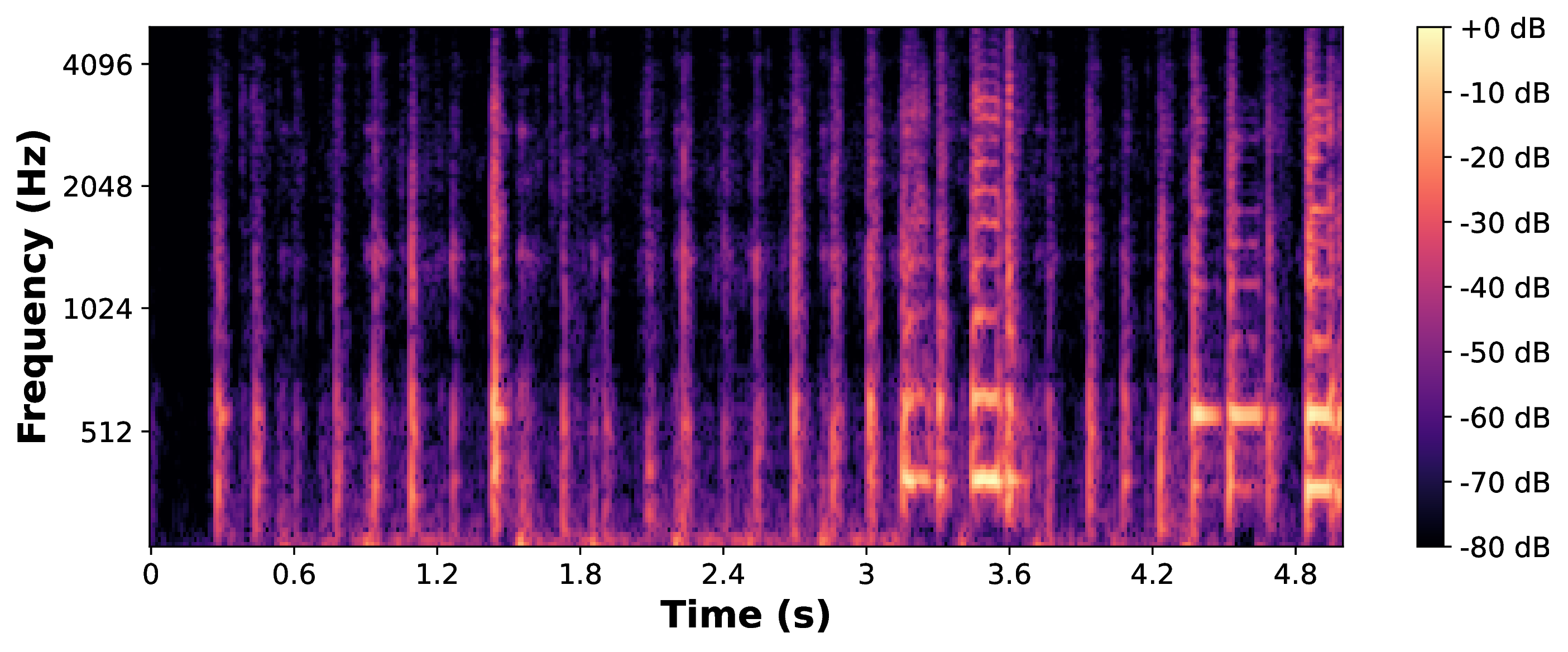
|
Guitar Playing with VCTK Model
Example of guitar playing with a model trained on continuous speech. Its encoder can then be used as a fixed representation to train other models in a “Grafted” approach.
Tonal and Percussive Rendering for Different Representations
The following table presents audio examples of transformations of different violin articulation excerpts, processed by models trained on the same data, but which learn different representations.
It seems that one-phase models, and models grafted with one-phase encoders, learn representations with a good capacity of tonal rendering, where a tonal input seems to “bleed” through the model (highlighted in blue). Models trained on a two-phase approach, or grafted with a two-phase encoder, seem to render atonal outputs even in presence of tonal inputs, a phenomenom through which the model seems to “hallucinate” atonal sounds in response to a tonal input (in orange).
| Bowing behind the bridge | Ordinario | Jeté/Ricochet | ||
|---|---|---|---|---|
| Input | ||||
| Animals | Two-Phase | |||
| One-Phase | ||||
| Grafted (one-phase) | ||||
| Dice | Two-Phase | |||
| Grafted (two-phase) | ||||
| One-Phase | ||||
| Music | Two-Phase | |||
| One-Phase |